以前在infra的時代,都是一個人顧幾百台的server,其中當也幾台是GPU server,可惜當時只知道怎麼維運監控報修打雜;在學校時設備前人都弄好了,超很混只會下nvidia-smi或是device = torch.device("cuda" if torch.cuda.is_available() else "cpu"),實際上對GPU的知識並不是很了解、怎麼選也不知道。同時網路上好像一直都沒有什麼完整的整理有關LLM可能需要知道的GPU知識,都是需要了才查,因此筆者這邊自行整理了一些常用的內容。
所以這章要來深入研究LLM相關的GPU基本知識!
Mythbusters Demo GPU versus CPU
回顧這個非常有名的影片,可以明顯看到在CPU一個一個點出圖片時,GPU可以同時點出一幅畫,表達平行計算的力量。
因為我們最常用的還是NVIDIA的GPU,所以我們可以從 官方文件 中看到CUDA Compute Capability對應的精度,精度部分在Day3介紹過。
| CUDA Compute Capability | Example Devices | TF32 | FP32 | FP16 | BF16 | INT8 | FP16 Tensor Cores | INT8 Tensor Cores | DLA |
|---|---|---|---|---|---|---|---|---|---|
| 9.0 | H100 | O | O | O | O | O | O | O | X |
| 8.9 | RTX 40 | O | O | O | O | O | O | O | X |
| 8.6 | RTX 30、A4000 | O | O | O | O | O | O | O | X |
| 8.0 | A100 | O | O | O | O | O | O | O | X |
| 7.5 | T4、RTX 4000、RTX 20 | X | O | O | X | O | O | O | X |
| 7 | V100 | X | O | O | X | O | O | X | X |
這邊筆者把跑LLM不太會使用的8.7和FP8拿掉了,可以看到CUDA Compute Capability是8以上才支援BF16和TF32,但是CUDA Compute Capability不等於GPU的計算性能。
從CUDA Compute Capability看出的是GPU的架構和演化:
6.x:Pascal 架構 (2016) - 支持FP16。
7.0:Volta 架構 (2017) - 支持FP16 Tensor Cores加速。
7.5:Turing 架構 (2018) - 引入RT Cores,讓遊戲畫面更加生動真實。
8.x:Ampere 架構 (2020) - 支持BF16。
8.9:Ada Lovelace 架構 (2022) - 提升了光線追蹤和AI的計算能力,用在RTX 40系列。
9.x:Hopper 架構 (2022) - 進一步提升AI的計算能力。
官方有整理了 常見的GPU對應的Compute Capability ,但不是全部的型號都在上面。
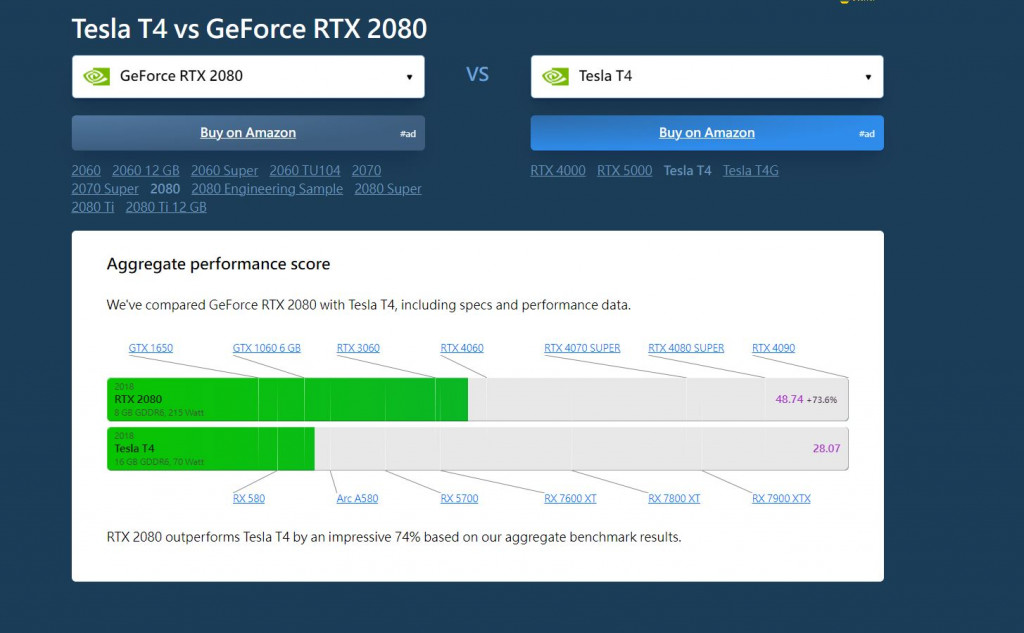
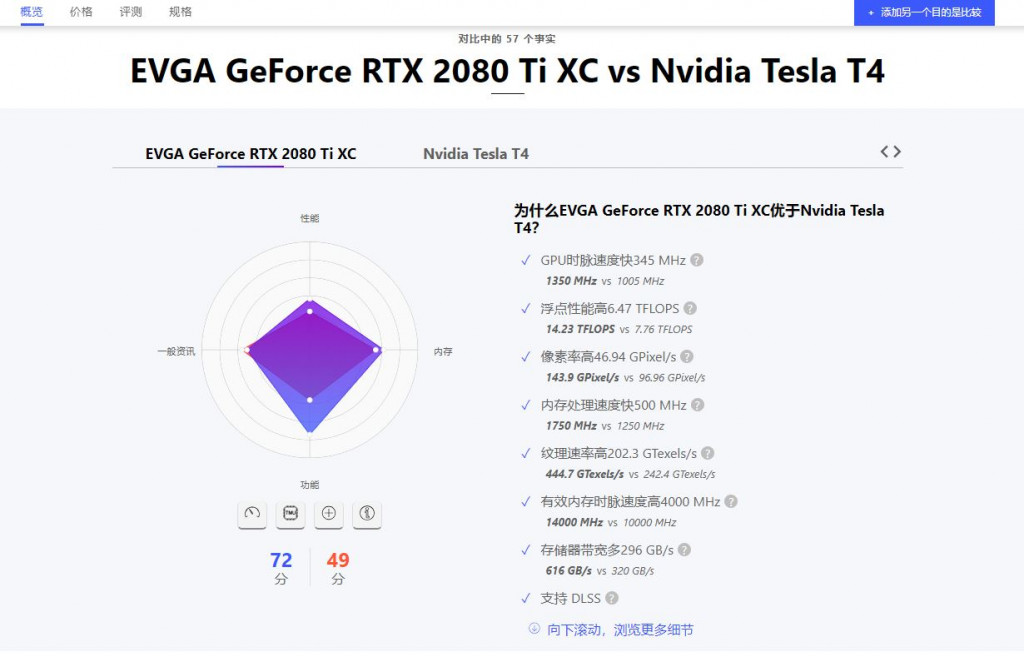
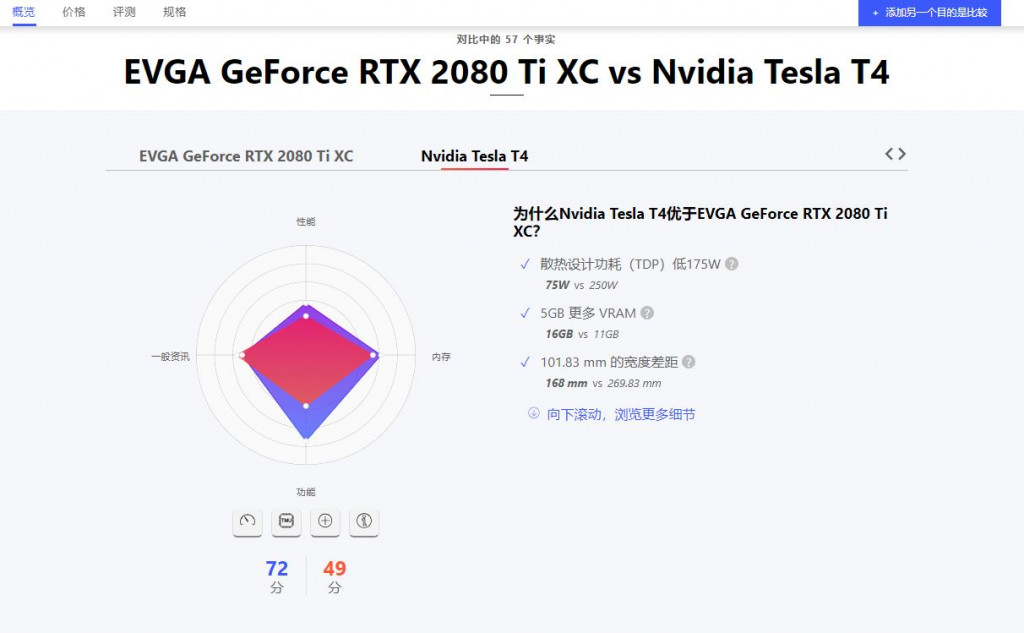
至於計算性能的部分,可以從核心數量、Clock Speed、FLOPS、Memory Bandwidth等等去判別,像是Tesla T4就是GeForce RTX 2080大約1/3的Clock Speed,整體而言運算速度比較慢,將兩個GPU名稱google,很多網站都會有漂亮的比較圖和表格可以看,就一般跟選電腦一樣。
(網站截圖)
(網站截圖)
雖然整體來看2080都比T4好,但T4的VRAM更多一點,當然筆者兩個都不推薦使用。
(網站截圖)
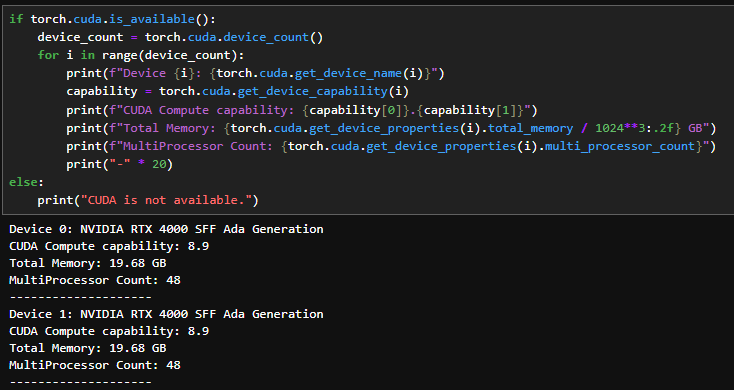
如果已經有電腦了,懶得去官網對照版本的話,也可以試試這段程式碼 (來自GPT-4o):
import torch
if torch.cuda.is_available():
device_count = torch.cuda.device_count()
for i in range(device_count):
print(f"Device {i}: {torch.cuda.get_device_name(i)}")
capability = torch.cuda.get_device_capability(i)
print(f"CUDA Compute capability: {capability[0]}.{capability[1]}")
print(f"Total Memory: {torch.cuda.get_device_properties(i).total_memory / 1024**3:.2f} GB")
print(f"MultiProcessor Count: {torch.cuda.get_device_properties(i).multi_processor_count}")
print("-" * 20)
else:
print("CUDA is not available.")
筆者不久之前遇到裝好GPU下nvidia-smi時出現以下不明錯誤訊息:
Unable to determine the device handle for GPU0000:01:00.0: Unknown Error
開機時還正常,但過了一陣子之後機器突然完全檢測不到GPU,一開始都是往驅動程式那邊去檢查的,但後來發現其實就是過熱的問題!
為了證實這個猜測只好重開機,然後一路監控他的溫度。
這邊用的是gpustat檢查,一開始沒用到GPU都很和平。

一用到GPU後,電腦出現溫室效應,溫度不斷升高,幾分鐘內上升了60度......最終在100度時炸裂了! 又開始出現Unable to determine the device handle for GPU0000:01:00.0: Unknown Error。


最後只好再重新開機一次,組裝風扇。
網路查了很多人也遇過這個問題,基本上都是過熱、缺電兩種狀況。
消費級
主要個人用戶或遊戲玩家,讓他們有高畫質和高幀率的遊戲體驗。高核心頻率、較高的顯存頻寬,通常支持最新的遊戲技術如光線追蹤 (Ray Tracing)和深度學習超採樣 (DLSS)。
代表產品:NVIDIA GeForce RTX系列,AMD Radeon RX系列。
企業級 / 專業級
面向專業應用,如科學計算、數據分析、機器學習和人工智慧等。優化於穩定性和精度,支持更多的平行計算任務,通常有更高的浮點運算能力。
代表產品:NVIDIA Quadro和Tesla系列(如A100、V100),AMD Radeon Pro和Instinct系列(如MI100)。
這兩個的分類其實只是針對常見客戶,NVIDIA的使用政策上在企業級顯卡有一些國家的出口限制在,像是中國賣的A800、H800等等。至於商業用的部分,企業級可能需要特定商業授權,這部分可能就需要再查查了。企業如果AI需求不大,也可以買消費級的顯卡。
我們現在知道GPU的選擇除了預算之外,更重要的是看你的精度需求,可以從NVIDIA GPU CUDA Compute Capability去查詢。在企業級的顯卡部分可能需要注意一下它的商用使用限制。現在對GPU的選擇稍微有底了,下一章我們可以繼續看看VRAM的部分!

一文读懂GPU的过去、现在和未来 (2023年底的文,有寫到很多歷史和每種架構的詳細介紹)
https://livevideostack.cn/news/interview-20231226/
NVIDIA英伟达所有GPU显卡算力及其支持的精度模式 (整理的很好懂)
https://blog.csdn.net/chan1987818/article/details/132894362
GPT-4o 修稿 CPU / GPU / NPU / TPU、消費企業級顯卡的部分


 iThome鐵人賽
iThome鐵人賽